[译]改进 Grafana Mimir 的查询性能:为什么我们在存储网关中放弃了 mmap?
作者:Charles Korn
译者:aimuz
最近几个月,我们一直在努力改进Grafana Mimir的性能,这是一个开源的、水平可扩展的、高可用的、多租户的时序数据库,用于长期存储指标数据。在之前的博文中,Mimir 的工程师 Dimitar Dimitrov 和 Marco Pracucci 介绍了 存储网关(store-gateway) —— Mimir 中负责优化从对象存储中获取指标数据的服务 —— 并详细介绍了我们为了处理查询内存溢出的问题
在本文中,我想更深入地研究存储网关(store-gateway)的内部实现,重点关注索引头(index-header),这是保持查询性能的关键组成部分,以及一个我们最近解决的由 mmap 引起的性能和稳定性问题。这次优化是我与 Nick Pillitteri 一起完成的工作,并在 Steve Simpson 之前的调查基础上进行的。
什么是索引头(index-header)?
索引头(index-header)是 Mimir 使用的 Prometheus TSDB 块索引的一个子集,它允许存储网关(store-gateway)在不需要从对象存储下载整个块的情况下高效地响应查询。
Mimir 基于 Prometheus,因此使用 Prometheus TSDB 格式来存储获采集到的时间序列数据。Prometheus 设计为在具有本地硬盘的单个节点上运行,而 Mimir 利用像 Amazon S3 或 Google Cloud Storage (GCS) 这样的对象存储来实现单台机器难以达到的高性能和可扩展性。
鉴于对象存储具有不同的性能和成本特性,Mimir 在 Prometheus 存储格式的基础上进行了扩展,以提供高性能而不会导致账单成本过高。 Mimir 与 Prometheus 一个具体的不同之处在于为每个块使用索引头。(块是时序数据的存储单元;许多 2、6 或 24 小时时间窗口内的时间序列被压缩并存储在一个块中。)
索引头仅包含每个 TSDB 块索引的一部分信息 —— 就是存储网关(store-gateway)决定一个块是否包含与查询匹配的时间序列以及如果是,需要加载哪些块的部分来检索相关数据所需的最小信息。这允许存储网关(store-gateway)在响应查询时只检索块的一个子集。块的大小可以达到多个 GB,但是大多数查询只需要从块中获取几 KB 的数据。
索引头(index-header)仅包含每个 TSDB(时间序列数据库)块的部分索引,足以让存储网关(store-gateway)决定一个块是否包含与查询匹配的时间序列数据,并确定需要加载哪部分的块来检索相关数据。这允许存储网关(store-gateway)在响应查询时只检索块的一个子集。块的大小可以达到数 GB,但大多数查询只需要从块中获取几 KB 的数据。
(如果您好奇并想更多了解 Prometheus TSDB,我们的同事 Ganesh Vernekar 写了一系列优秀的文章介绍它的内部工作原理以及它如何在磁盘上存储数据。)
什么是 mmap?
mmap 是一个系统调用,它使应用程序可以像访问普通内存一样访问文件。可以把它看作是传统文件 I/O 的神奇替代方案。
使用传统的文件 I/O 读取文件时,应用程序会为文件内容分配一些内存,并请求操作系统将部分或全部文件读入该内存。如果应用程序不想立即将整个文件读取到内存中,它可以要求操作系统只读取文件的一部分。然后在应用程序完成读取第一部分后,指示操作系统加载后面的部分。
相比之下,使用 mmap 时,应用程序会要求操作系统将文件映射到内存中,操作系统会返回一个内存地址,应用程序可以从那里读取文件。从应用程序的角度来看,它就像读取其他普通内存一样读取那块内存。
在底层,操作系统管理着将文件内容加载到内存和卸载出内存的过程。每当应用程序尝试读取当前未加载的文件段时,就会发生页错误(page fault),应用程序线程会暂停,操作系统加载所需的文件部分到内存,然后恢复线程的执行。操作系统还卸载最近未读取的文件部分,从而允许该内存用于其他用途。
这种行为使得应用程序可以像使用缓存一样有效地处理映射文件,操作系统会根据访问模式和其他启发式方法(如系统内存压力)来管理每个文件中可立即读取的部分的大小。这正是 Mimir 使用 mmap 的目的:store-gateway 会利用 mmap 加载索引头,并将其管理工作交给操作系统。
像水油不相溶一样:为什么 mmap 和 Golang 不兼容
我们在Grafana Cloud Metrics中运行着数十个 Mimir 集群。在这些集群中,我们看到部分 store-gateway 实例在处理查询请求时变得非常缓慢甚至无响应。这意味着我们的客户有时会遇到较慢的查询和错误 —— 这不是我们想要的结果,因为他们依赖我们的技术栈来监控自己的业务关键系统。
我们观察到一些其他症状似乎与这种延迟和错误率相关。特别是在这些问题发生期间,发现索引头加载活动增加,并且实例健康检查超时。这些健康检查非常简单:Kubernetes 对 store-gateway 实例上的 /ready 路径发出 HTTP GET 请求,store-gateway 返回 HTTP 200 响应。一旦 store-gateway 完成启动,应该是即时响应的,但它们的响应时间超过了 1 秒。
换句话说,似乎是索引头加载活动增加时,整个 store-gateway 进程出现停顿。
我们认为这是由于使用 mmap 来加载索引头造成的,Steve Simpson 通过设置一个从引入人为 I/O 操作延迟的 FUSE 文件系统加载索引头的小测试来验证了这一点。
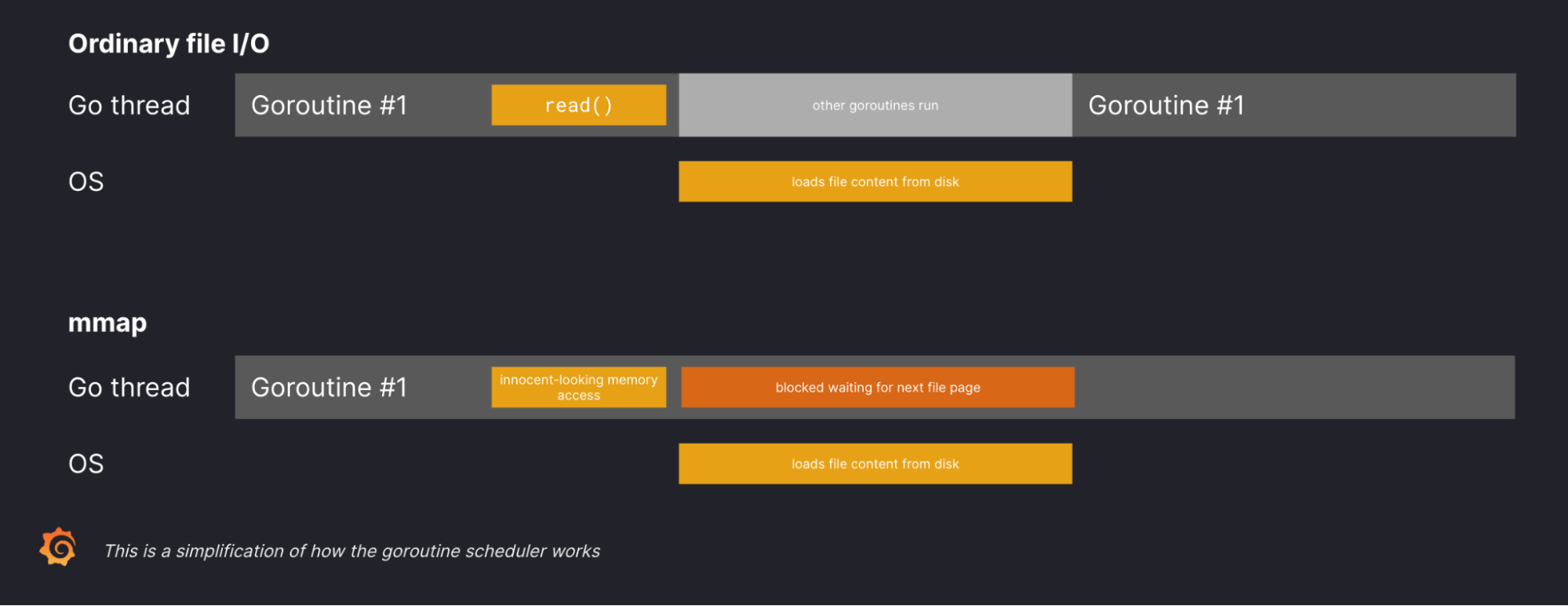
为什么使用 mmap 会导致整个进程停滞不前?如果一个 goroutine 执行常规的文件 I/O 系统调用,Golang 的调度器会暂停该 goroutine,同时操作系统会完成系统调用,并利用底层的操作系统线程来运行另一个 goroutine。当系统调用完成后,Golang 的调度器将恢复原来的 goroutine。
然而,当一个 goroutine 访问需要从硬盘加载的映射内存时,会发生页面错误(page fault),并且底层线程会被阻塞直到所需的数据从硬盘加载。从 Golang 调度器的角度来看,该 goroutine 正在忙于等待数据加载,所以无法使用该 goroutine 所在的底层线程在操作系统从硬盘加载数据时运行其他 goroutine。Golang 进程使用有限数量的线程,如果多个 goroutine 同时触发页面错误,它们可能会消耗所有可用线程并导致进程出现挂起的现象。
我发现这个可视化对比很有助于理解 Golang 中常规 I/O 和 mmap 的区别:
解决方案:再见,mmap
那么,我们是如何解决这个问题的呢?答案在概念上很简单 —— 用普通的文件 I/O 操作替换 mmap 的使用 —— 但实际实现却更复杂。
除了修改一些严重依赖 mmap 魔法的复杂代码之外,我们还需要通过多轮优化来实现与 mmap 类似的性能水平,因为我们不再能依赖操作系统在内存中缓存最近使用的索引头。
以下三个优化尤其重要:
缓冲 I/O。索引头的每个字段都很小,所以对每个字段进行单独的读调用是非常慢的。使用缓冲 I/O 意味着我们在内存中缓冲文件较长的一段,从该缓冲区读取各个字段,并在用完缓冲区后重新填充它,从而显着减少读取调用的次数。
为每个索引头(index-header)建立文件句柄池。索引头第一次加载时,我们只加载头的一个子集到内存中,因为在每个块都保持完整的索引头会占用大量内存。当后续查询到达查询该块时,我们使用这个预加载的子集来定位需要读取的头的相应位置,然后从硬盘读取它们。但是,我们发现仅仅打开文件进行读取的操作就非常慢。当我们为每个索引头引入了文件句柄池,就不再需要在每次进行昂贵的打开操作,只需要定位到文件中的适当位置并开始读取。
不再为每个标签名称创建新的字符串实例。 索引头的一部分是倒排偏移表,包含了块内的每个标签名称和值对,以及一个指向所有拥有该名称/值对的系列的列表的引用。该表按名称和值进行排序,因此所有具有相同名称的名称/值对彼此相邻。在我们的原始实现中,我们简单地读取名称和值,为每个对实例化一个字符串。但是,这意味着我们为相同的名称创建了可能数十个字符串,增加了内存消耗。当我们修改了索引头读取器来重用现有的字符串名称(感谢 Golang 编译器执行的优化),我们看到内存使用量大大减少,并且由于减少了所有不必要字符串带来的垃圾收集压力,CPU 使用率也有所降低。
影响:健康检查不再超时
我们已经将不使用 mmap 的 store-gateway 运行了近 6 个月,这与我们最近做出的其他改进一起,显着改善了它们的性能和稳定性。
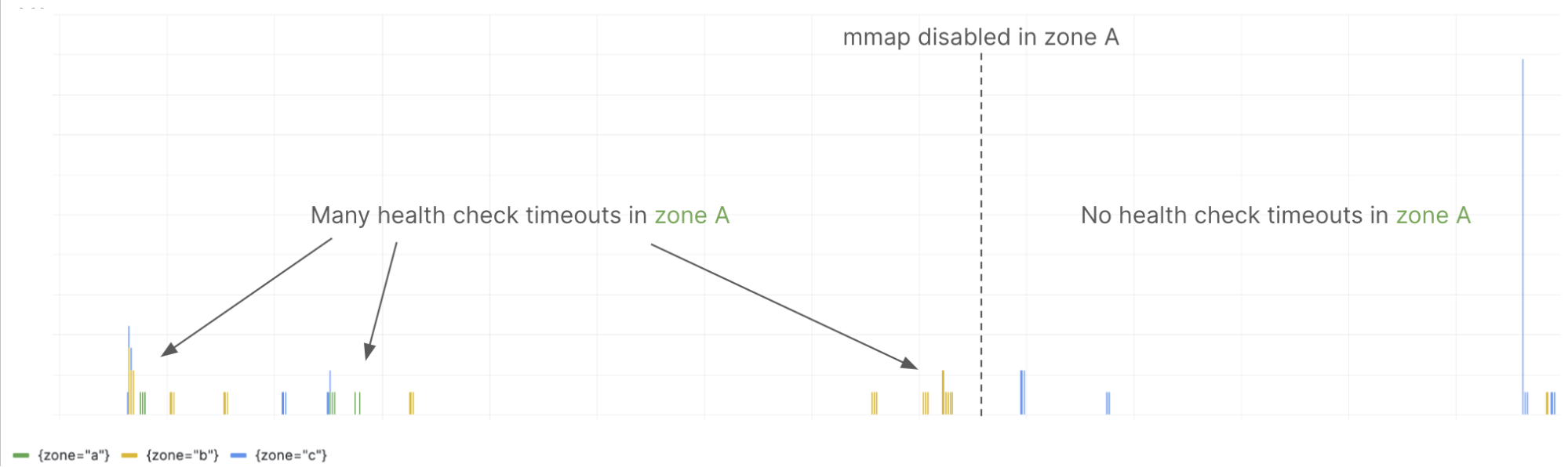
我之前写过,我们看到大量的健康检查超时。部署此更改后,我们发现健康检查超时基本消失了。例如,我们为每个 Grafana Cloud Metrics 集群运行三个 store-gateway 区域,下图显示了在一个集群中禁用 mmap 前后每个区域的健康检查超时率:
更好的是,这个修改现在在开源的 Mimir 中也可用,并在 v2.7 版中默认启用,因此每个人都可以从这个改进中受益。如果您有兴趣查看这些变更背后的代码,请查看 这个 GitHub issue 中链接的 PR。
Grafana Mimir 的下一步
除了从 store-gateway 中删除 mmap,我们还对 store-gateway 进行了优化,通过逐步从对象存储读取数据,并以更有效的流式方式发送给 querier 来消除内存溢出错误。
在未来的文章中,我们将介绍 Mimir 的其他改进,包括 querier 如何利用流以及 store-gateway 中引入的优化来查找与标签匹配器匹配的序列,同时降低 CPU 和内存利用率。
要进一步了解 Grafana Mimir,请查看我们的免费网络研讨会“Grafana Mimir 简介:可扩展到 10 亿指标及以上的开源时序数据库”以及我们的 Grafana Mimir 文档。